Databricks - LLM in production
Wonderful walkthrough! Full credits to Databricks!

Applications with LLM: This is a very cool package of important information on LLM and how it can be used in production, important aspects to consider.
Know about Pretrained LLM (what tasks it can solve)
Hashing the problem and breaking it down into a known set of NLP tasks.

Having a clear abstraction between Given input and Generate output
Choose the library or framework. I would add Haystack, and Cohere as well. Classical or workflows.

Pretrained model selection is crucial. Pipeline in hugging face abstracts away most things we can do. It picks the LLM and does the task. Chaining these into the custom pipeline is what we want to do in production.

6. Tokenizer and Model are building blocks in doing any task - finetuning, in-context learning, etc. This in turn has different flavors in terms of CausalLM, Seq2SeqLM, etc.



Generate method represents the decoding strategy for performing inference from the model or a particular checkpoint. These output parameters and tokenizer parameters are very important.
Datasets - If there is a FAQ dataset you want to fine-tune the models on, maintaining a dataset in the private organization if it’s confidential will help in a good version control pipeline.
Picking the right LLM for the task: Filter by needs - model size, updates, and most important commercial license. Trade-off - cost, performance, latency.
Another factor - Variants (base, large, XXL) - Generalist for language understanding or task-specific (already finetuned). Check the open LLM leaderboard to see the ones that are performing well in NLU.

https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
https://github.com/declare-lab/instruct-eval - Specifically for Instruction tuned models.
https://declare-lab.net/instruct-eval/ - Certain models are tuned for instruction-following similar to the chatGPT conversational model.
https://jarvislabs.ai/docs/llmchat/ - Love this one too.
NLP tasks vs Models: Sentiment Analysis, Summarization, Conversation/Chat, etc. Zero-shot vs Few shot learning (alternative to fine-tuning if LLM is decoder generalist) - prompting with few examples.
Prompts - Powerful way to interact with LLM. Interacting with AI is a skill. Foundation models are basically a Next word predictor, masked language modeling - which is very efficient in writing plausible sentences and qualified in language understanding. To make it work on problem-solving, we use models tuned to follow instructions or prompts. Prompting to elicit a response is key.
Chain LLMs output when needed. Maintain the structure of the prompt. Be explicit in instructions. It’s a balance.
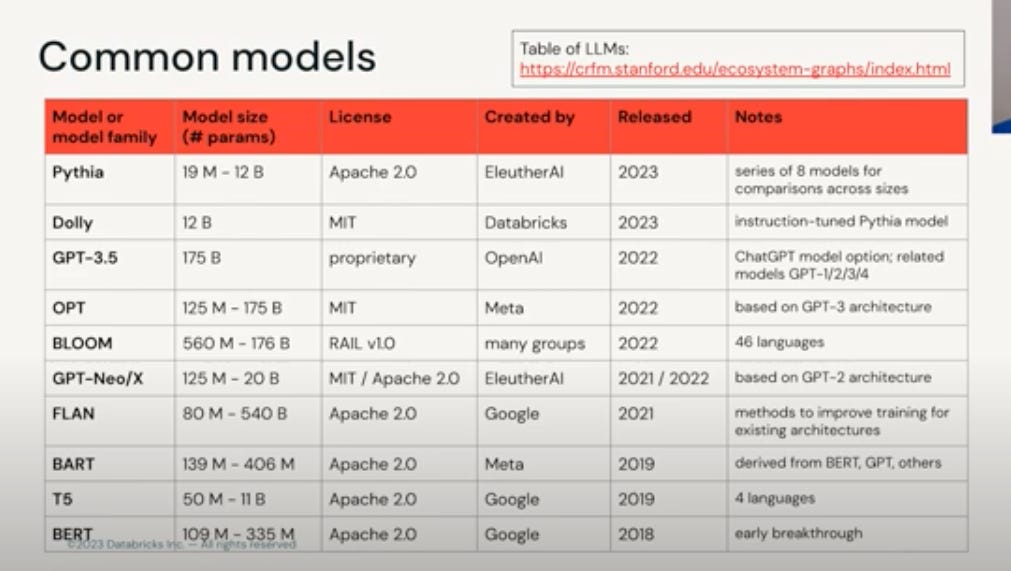

Prompt engineering - Understanding how prompting and generation works for the LLM we interact with is necessary. Tips - Instruction, context, Input/question, output type/format. Use Action words for the task that commands “classify”, and “summarize”.
Cognitive aspects surrounding it would also steer the model really well to utilize the reasoning and augment it much better than the raw generation from the model.

Explicit formatting rather than an assumption:

Manipulating inputs - it’s similar to the SQL injection analogy. Injection, jailbreaking, breaking the moderation, and giving out sensitive info.

Pick a dataset, and model - for a specific task. Using a straightforward HuggingFace pipeline for inference is an easy path. Playing with the generation parameters to decode or stream the tokens. Choosing the pre-trained or finetuned model that has overlap in requirements or tasks. Remember that there is a scope of catastrophic forgetting - so over-tuning in a way is not overfitting to a specific task. Zero-shot on these would be a little random in probabilities.
Few-shot learning demands a larger model to generalize. Take care of the delimiter and end of tokens in context.
Another key aspect - How we can search and sample in inference during text generation - Inference config - Search (Greedy (single next likely token), Beam (considering several sequence path). vs Sample - (Top-k (k likely tokens), Top-p (upto probability mass p)
Usage of Auto Loaders, Tokenizers - Independently load individual mode and tokenizers (Text → Tokenizer → Model → Tokenizer → Decode token by token)
AutoTokenizer, AutoModelForSeq2Seq. Try using the cache whenever possible.
Add prefix to instruction + Input and then tokenize. There are Auto * based classes and also architecture-specific classes.
Embeddings, Vector DB, Search, RAG methods: Knowledge-intensive tasks - good decoupling services - Understanding vector database, plugins, libraries - to improve the search or retrieval performance.
Training, fine-tuning - in-context learning - put knowledge into LLM. It’s as simple as important notes taking and conditioning on it. Context processing also has a trade-off in cost and latency. We can turn the unstructured data into embeddings using any open-source or enterprise embedding vectors. Search, recommendation, classification, retrieval - there is an intersection. Outlier detection/In and out of the domain also could be useful.
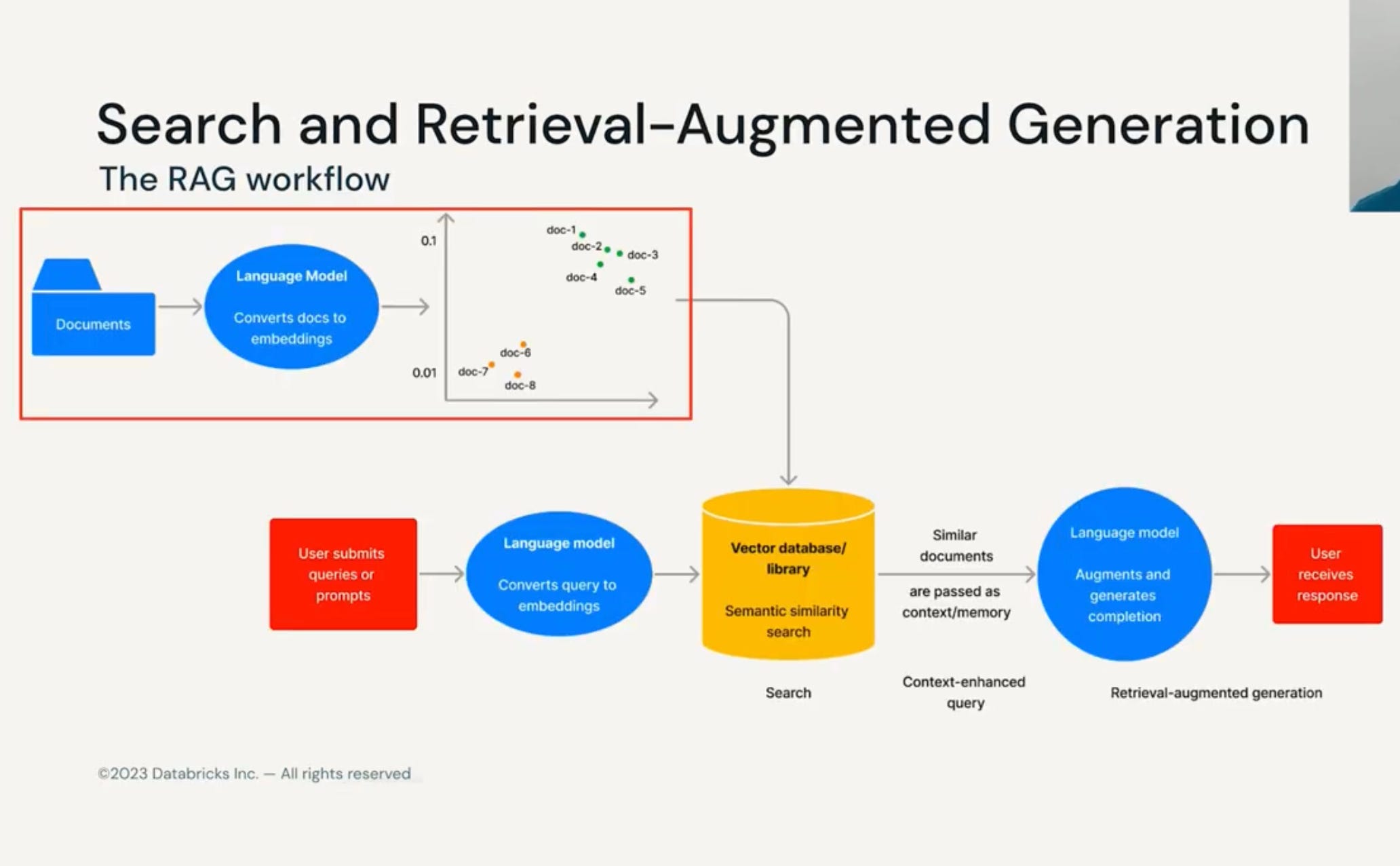
Retrieval Augmented Generation: Beginning approach on QA system. Choose the vector library or a database, and choose the embedding model (open source, enterprise)
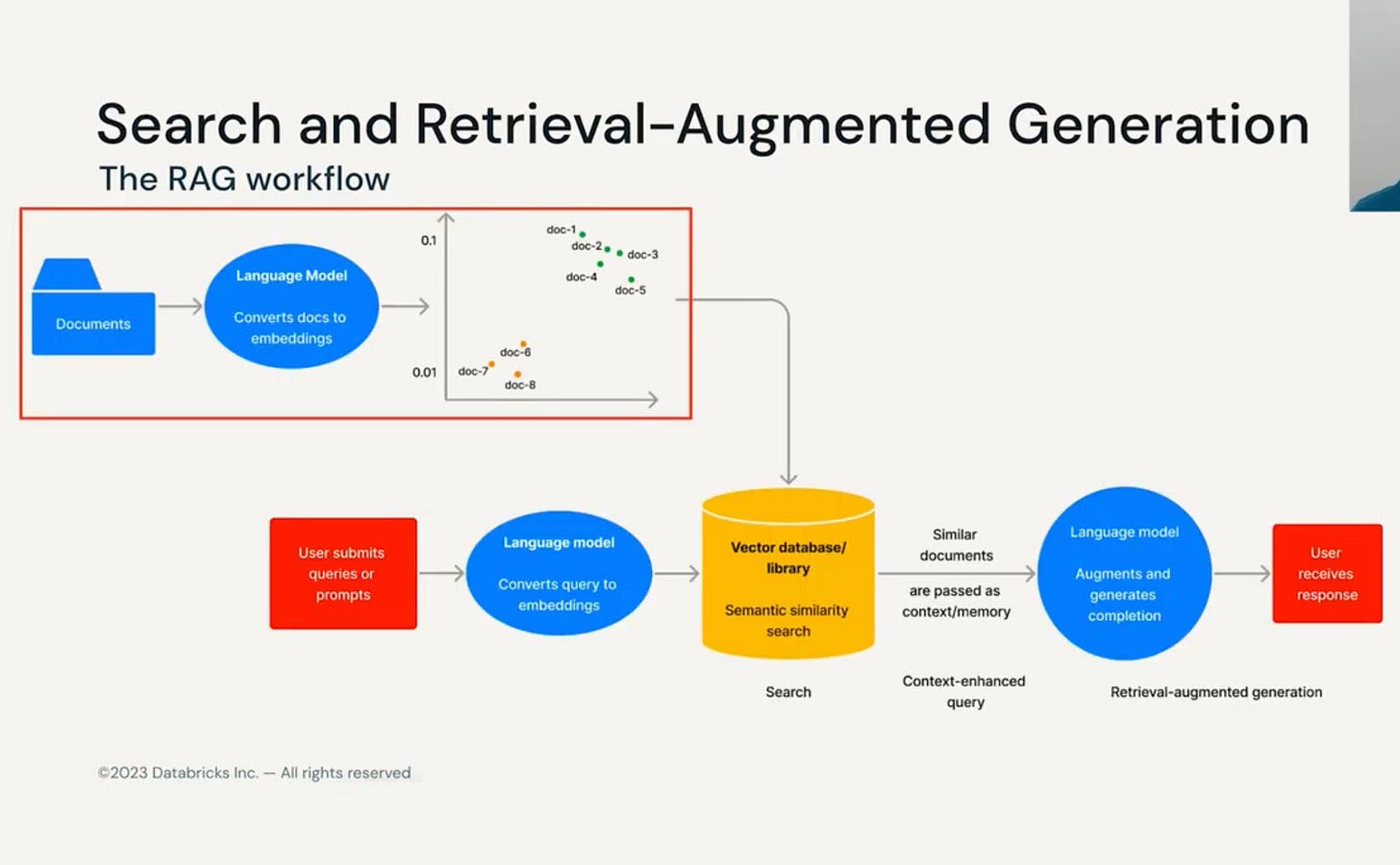
19. Vector Search - Algorithms like KNN (brute force search), ANN (less accurate but more speed) - indexing - help to conduct efficient vector search. Eg: Annoy, FAISS, HNSW, LSH, SCaNN) - Similarity metrics (Cosine, dot) - Reduce memory - using product quantization (no of bytes) - splitting a vector into sub-vectors and quantizing separately, using these sub-vectors to perform the nearest neighbor search. Indexing is fast - since query and stored vectors match is computed against a centroid rather than brute force. It could be graph-based too. To end, the search is amazing!

More to follow :)