Full stack deep learning LLM 2023 - How was it? 🪄 - Part 1
In short, it covers all significant aspects of LLM!

First session LLMOps:
Key aspects:
1) Trade-off between proprietary and serving open-source models. To what extent we can use proprietary and utilize the language reasoning to the fullest, how we can run feedback, and augment the product with open source?
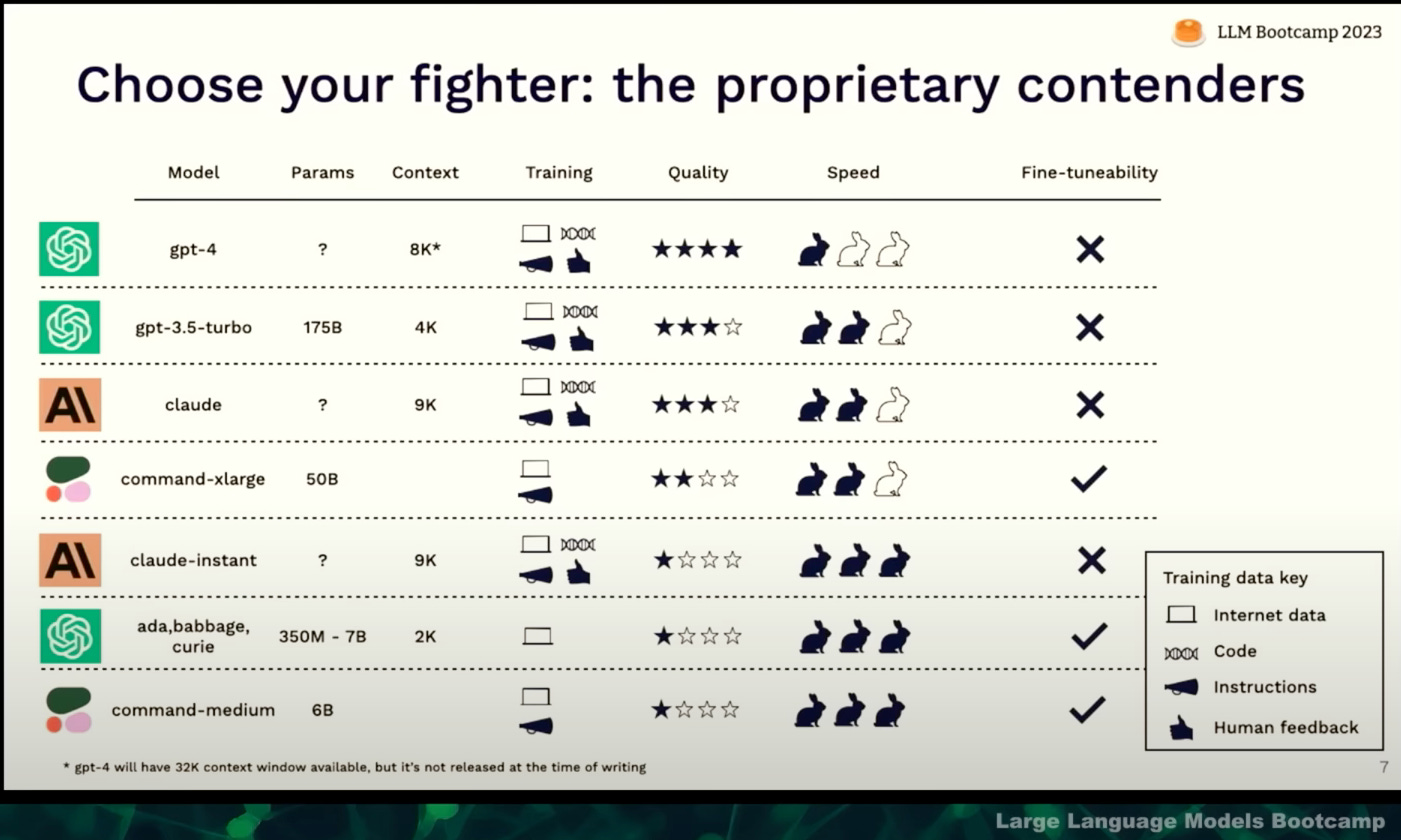
There might be a few other differentiating factors between these models that are needed to make it a little more intuitive for tasks that could be delivered using those models. Quality might not be directly proportional to params, this is something I wanted to try out for a particular task in my organization and benchmark each of these models.

2) Feasibility check of task with larger enterprise models - and then go towards customization, inference, and integrations.
3) "Prompts" - This is something I feel uncomfortable with when asked, "How good the prompt is?" -> Given the token influence, how good is it to have the dynamic input added to prompts? Benchmarking, speaking with evidence - much needed in prompts before pushing to production.
There are various experiment-tracking tools emerging in this area, these were difficult questions that need careful research in implementation. One such survey I got, seemed to ask the right questions.

4) Checking the distributions of "text" and benchmarking solutions taking into account ad-hoc customer conversations. In text generation LLM, the high-level tasks of clustering, intent detection, topic modeling, semantic search, and keyword detection - are always good starting points.
5) Framework for Testing LLM: - Coming up with a demonstrable "evaluation dataset" - adversarial examples, "Instruction tuned models" might help in generating these datasets. To test the QA task by LLM, we can generate different ways of asking questions to pick the failure modes. - One such cool piece of work https://github.com/rlancemartin/auto-evaluator - Apart from thinking about testing LLM, there is a need to benchmark the test dataset too - to see how much coverage it provides to aspects around the task.

6) Improving: There are packages like Guardrails which could be used to develop a chain of thought prompting execution and compare it to the LLM predicted solution on the specific task.
Overall it’s wonderful 🚀! Needs research in implementation across each aspect, choosing the base LLM, coming up with a prompt chain, Testing, and Deploying the service, checking the distribution, and interaction data from users, and fine-tuning the workflow to incorporate the interaction data distribution.
Second Session: Langchain + Q/A Demo ☀️
Before predominantly we considered LLM as a source, now with frameworks coming up, the core idea considers the “value the product offers” alongside having LLM as a tool kit in the entire arsenal of the technological stack.
Overall, abstraction is the key! Frameworks like Haystack, and Langchain → couple together the functionalities whilst using LLM as a powerful generation tool.
The idea behind context: Smaller than the internet and maximum tokens generation model supports, bigger than the instruction. Thought about the impact of context window size. 'chunking and making multiple inferences' vs 'higher context length results' -> humans might have a multi-hop pattern - hence attending to important info in multiple hops vs "attending to huge info which may have much unnecessary info" - As there is one way of doing it Vector DB + retrieve important + generate with context - Thinking about the question of "context window" might be critical for all NLP SAS companies.
Another key abstraction is coupling the prompt + task-based (prompt chain for a task). Prompt templates - that maintain different versions of prompt for each task.
Prompt effect tracking - “Building the intuition” - I felt this when conversing about some topics in chatGPT, I sometimes respond with “Are you sure”. On the second thought of reasoning, it either apologizes or confirms the probability of being correct. There might be a set of intuitions captured when using it for coding assistance, using it for reasoning, summarizing, etc. Visualizing these intuitions is key to better understanding.
In copilot, these intuitions are modeled as “time in accepting the suggestion”, execution after which it might get rolled back, based on run-time errors on those recommendations - it is not only technical aspects, there is a chunk of user perceiving aspect.
There was an interesting discussion on a few shot chain of thought prompting + retrieval augmented generation! → combining multiple techniques without hitting the prompt limit. Though it depends on the use-case, it’s actually a good way of explainability. “Agent Driven” Breaks down the intermediate steps and calls out different APIs to perform tasks in sequence. “Separation of concerns” seems to be a good fit in software 1.0 (software engineering), in LLM engineering → it might increase the number of API calls we make as we decompose. It’s for sure a trade-off - whether we want to increase precision by making several calls of concern or to stuff and extract how many generations we are close to confident with.
Integration of vision in LLM framework: I still want to understand more about the “Agent framework” - as autonomous is sometimes overplayed.
We humans are amazingly complicated generative models - I got a “gift card” with a birthday wish from a friend who I don’t know yet who has sent, but I have generated multiple modalities of visualizing the person, wish, audio with environments of emotions on happiness, suspicious, excited, questioned, ambiguous. I could coreference multiple aspects. I tried to mimic my thought process in prompts, but sometimes we have to make it simple, that’s the idea behind effective prompts.
Explainability: Right now the “source”, highlight of document expansion, and tracing the token level influence are not there yet.
Overall, it’s always amazing to have such developer frameworks in the toolkits to solve problems that could be prototyped for feasibility or enhance the value of existing products with LLM. I loved the conversation. 🚀
You have reached the end of two informative sessions!
Share if you like ✍🏻! More is on the way, it’s a start, increments in its flow!